This Chinese AI Breakthrough Could Change How LLMs Are Built
What it is
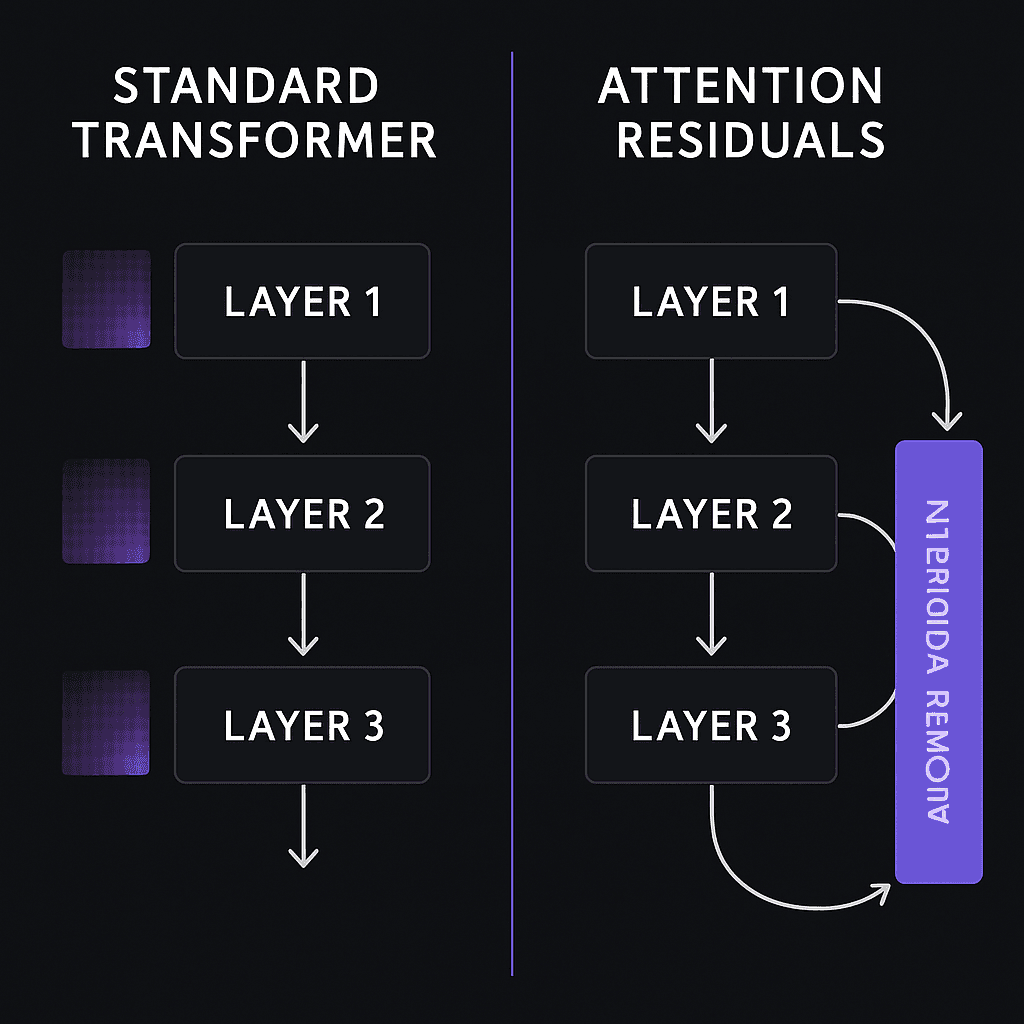
Standard transformers pass information layer-by-layer, but each layer's attention patterns typically vanish after use. Attention Residuals keeps a running 'memory' of those patterns—think of it as leaving breadcrumbs through the model instead of sweeping them away. The model can reference earlier attention states when making decisions in later layers.
Why it matters
If this scales, it could mean cheaper long-context models—less need to cram everything into giant parameter counts. For builders: watch whether major labs adopt this in next-gen architectures. For users: expect Kimi (and maybe competitors) to handle multi-turn conversations and long documents more coherently without the usual context-window hacks.
Key details
- •Published by Moonshot AI, the Chinese lab behind the Kimi chatbot
- •Core idea: preserve attention states across transformer layers instead of discarding them
- •Preliminary claims focus on improved context retention without proportional parameter increase
- •No public code release or benchmark comparisons mentioned in available material yet
- •Video explanation available on YouTube discussing the architectural change
Worth watching
 4:25:13
4:25:13State of AI in 2026: LLMs, Coding, Scaling Laws, China, Agents, GPUs, AGI | Lex Fridman Podcast #490
Lex Fridman
This Lex Fridman podcast directly addresses China's role in AI development alongside LLMs, scaling laws, and future AI architecture—providing comprehensive context for understanding Chinese breakthroughs in the field.
 10:25
10:25A New Kind of AI Is Emerging And Its Better Than LLMS?
TheAIGRID
This video explores emerging AI paradigms beyond traditional LLMs, which is directly relevant to understanding how new Chinese approaches might represent a fundamental shift in AI model architecture.
 40:22
40:22China’s Next AI Shock Is Hardware
CNBC